Karpathy LLM Wiki
 Greener-Dalii12k downloads
Greener-Dalii12k downloadsKarpathy's LLM Wiki implementation - multi-page knowledge generation with entity/concept pages and conversational query.
- Overview
- Scorecard
- Updates62

🧠 Karpathy LLM Wiki Plugin for Obsidian
AI-powered structured knowledge base that ingests your notes and generates a connected Wiki — based on Andrej Karpathy's LLM Wiki concept.
Obsidian official score 95/100 | Native support for 10 languages | Actively maintained, continuously evolving
English | 简体中文 | 繁體中文 | 日本語 | 한국어 | Deutsch | Français | Español | Português | Italiano
Official Site | Blog | Feedback & Discussion | 🤖 Explore Repo with DeepWiki
⚡ Quick Update Reminder: This project evolves rapidly with frequent bug fixes, performance improvements, new features, and UX optimizations. We recommend updating to the latest version regularly in Obsidian (Settings → Community plugins → Check for updates), or enabling automatic plugin updates to ensure the best experience.
📑 Contents
- 🧠 Karpathy LLM Wiki Plugin for Obsidian
💡 What is LLM-Wiki?
You write. AI organizes. You ask. That's it.
🎯 The problem. Your notes are a goldmine — people, concepts, ideas, connections. But right now they're just files in folders. Finding what relates to what means searching, tagging, and hoping you remember the thread.
✨ The fix. Andrej Karpathy suggested something elegant: treat your notes as raw material, and let an LLM do the architect work. It reads what you write, pulls out entities and concepts, and weaves them into a structured Wiki — complete with [[bidirectional links]], an auto-generated index, and a chat interface that answers questions from your knowledge.
📚 So you don't have to be the librarian. No deciding what deserves a page. No maintaining cross-links. No wondering if something is out of date. Drop notes into sources/ and the LLM reads, extracts, writes, links, and even flags contradictions — while you stay in flow.
🤖 And it's not another chatbot. ChatGPT knows the internet. LLM-Wiki knows you — or rather, what you've taught it. Every answer carries [[wiki-links]] back into your knowledge graph. Every response is a trailhead, not a dead end.
⚡ Why Obsidian + LLM-Wiki?
Obsidian is brilliant at linked thinking. But there's a catch: you're the one doing all the linking.
LLM-Wiki flips that. Instead of you building the graph by hand, the AI grows it with you. Add a note about a new concept — it finds the connections you'd miss. Ask a question — it walks your own knowledge graph and brings back answers with citations.
- 🔗 Your Graph View comes alive. New notes don't just sit there — they sprout links to entities, concepts, and sources. The graph grows organically, and the plugin maintains it: detecting duplicates, fixing dead links, bridging languages with aliases.
- 💬 Your notes learn to talk back. Search becomes conversation. "What did I write about X?" becomes a dialogue, with streaming responses and
[[wiki-links]]as breadcrumbs. Every answer is a path deeper into your own knowledge. - 🧠 Obsidian becomes a thinking partner. It stops being a cabinet for notes and starts being something that helps you think — surfacing hidden connections, flagging contradictions, remembering what you forgot you knew.
🚀 Quick Start
📦 Installation
🌟 Recommended — Obsidian Community Plugin Market:
- In Obsidian, go to Settings → Community plugins
- Click Browse and search for "Karpathy LLM Wiki"
- Click Install, then Enable
🌐 Or from the Community Plugin website — visit community.obsidian.md/plugins/karpathywiki and click Add to Obsidian to install directly.
⚙️ Manual (alternative):
- Download
main.js,manifest.json,styles.cssfrom Releases - In Obsidian, go to Settings → Community plugins. On the Installed plugins tab, click the folder icon to open your plugins directory
- Create a folder named
karpathywiki, drop the three files inside - Back in Obsidian, click the refresh icon — Karpathy LLM Wiki will appear under Installed plugins
- Toggle it on to enable
🔨 Development: git clone, pnpm install, pnpm build.
🔄 Updating
This project evolves rapidly — new features, bug fixes, and improvements are shipped frequently. We recommend keeping up to date:
Option A — Manual update (recommended):
- Go to Settings → Community plugins
- Click Check for updates
- Find Karpathy LLM Wiki in the list and click Update
Option B — Enable auto-update:
- Go to Settings → Community plugins
- Toggle on Automatically check for plugins updates
- New versions will be detected automatically; update manually at your convenience
💡 Why stay updated? Each release may include new features, performance improvements, and important bug fixes. We actively maintain this plugin — missing updates means missing out on a better experience.
🔑 Configure an LLM Provider
- Open Settings → Karpathy LLM Wiki
- Pick a provider from the dropdown (Anthropic, Anthropic Compatible, Google Gemini, OpenAI, DeepSeek, Kimi, GLM, MiniMax, LM Studio, Ollama, OpenRouter, or custom)
- Enter your API key (not needed for Ollama)
- Click Fetch Models to populate the model dropdown, or type a model name manually
- Click Test Connection, then Save Settings
🦙 Ollama (local, no API key): Install Ollama, pull a model (ollama pull gemma4 or ollama pull qwen3.5:27b), select "Ollama (Local)" in the provider dropdown.
🎛️ LM Studio (local, no API key): Install LM Studio, start its local server (default http://localhost:1234/v1), select "LM Studio (Local)" in the provider dropdown. LM Studio runs a built-in OpenAI-compatible server — API key field is optional.
See Model Selection Guide for details.
🎮 Usage
| Method | How |
|---|---|
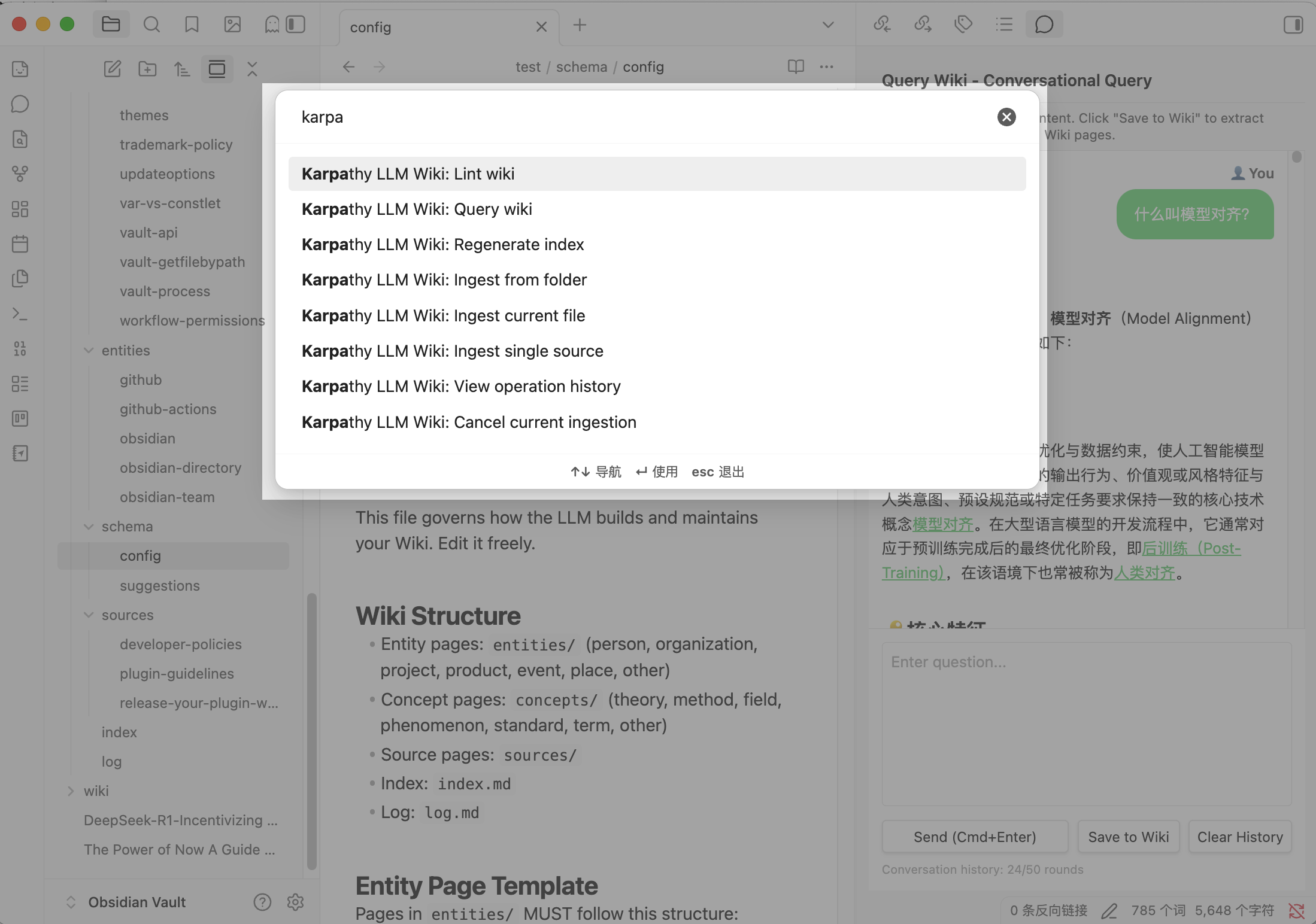
| 📥 Ingest single source | Cmd+P → "Ingest single source" — select a note to extract entities and concepts into Wiki pages |
| 📂 Ingest from folder | Cmd+P → "Ingest from folder" — pick a folder, batch generate Wiki from all notes inside |
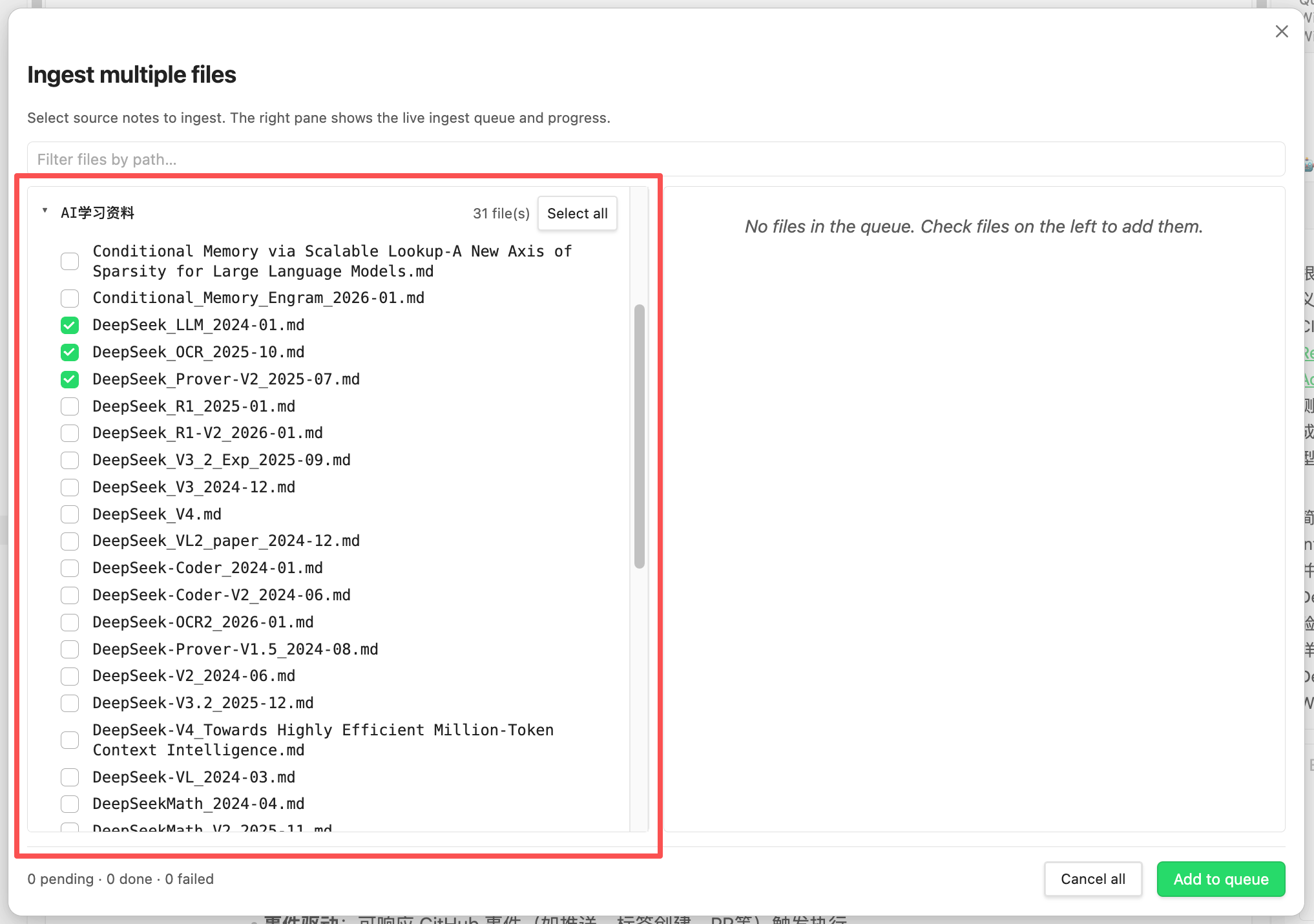
| 📑 Ingest multiple files | Cmd+P → "Ingest multiple files" — pick specific notes via two-pane modal (recursive folder tree + per-file checkboxes), then batch ingest the selection |
| 🔍 Query wiki | Cmd+P → "Query wiki" — ask questions, get streaming answers with [[wiki-links]] |
| 🛠️ Lint wiki | Cmd+P → "Lint wiki" — health scan: duplicates, dead links, empty pages, orphans, missing aliases |
| 📋 Regenerate index | Cmd+P → "Regenerate index" — rebuild wiki/index.md with current pages and aliases |
| 🎯 One-click ingest | Click the sticker icon in the left sidebar or Cmd+P → "Ingest current file" — directly ingest the file you're editing |
Re-ingesting the same source does incremental updates on entity/concept pages (new info merged in). Summary pages are regenerated.
💡 Smart Batch Skip: When ingesting a folder, the plugin automatically detects already-processed files and skips them to save time and API costs. The batch report shows skipped count.
⚠️ Upgrading from an Older Version?
This release is fully backward-compatible. No breaking changes since v1.0.0 — your existing wiki pages, settings, and workflows are preserved. No reconfiguration or data migration needed.
Upgrading to v1.20.3 from any earlier version: source-page slugs are now fingerprinted (every sources/<slug>.md becomes sources/<basename>_<6hex>.md). On your next ingest, existing sources/ pages are renamed in place and all [[sources/<slug>]] backlinks update automatically — no action required, but the file rename may briefly appear in your Obsidian file explorer. If you have external scripts or bookmarks that reference sources/<slug>.md paths directly, update them to use the new fingerprinted names.
If your existing Wiki was built across many versions, some pages may lack recent capabilities (aliases, alias-aware dedup, modernized prompts). Run Lint Wiki to see what needs attention. Smart Fix All handles the most common cleanups in one click.
If upgrading from a version before v1.16.0, run Lint Wiki once to automatically fix historical issues:
- Double-nested links
[[[[entities/Foo|Foo]]]]in log.md — Lint detects and fixes these with zero LLM cost - Cross-directory stub duplicates — pages that exist in both
entities/andconcepts/with the same slug are now correctly matched
For wikis built across many versions, follow these steps to bring your Wiki up to current standards:
1️⃣ Rebuild your index
Cmd+P → "Regenerate index" — This rebuilds wiki/index.md with alias entries for every page, enabling alias-aware search (e.g., searching "DSA" finds "DeepSeek-Sparse-Attention"). The old index format only listed page titles.
2️⃣ Run Lint wiki
Cmd+P → "Lint wiki" — This scans your entire Wiki and shows:
- 🏷️ Missing aliases: Pages without aliases (any version, if you never ran "Complete Aliases"). Click "Complete Aliases" — the LLM generates translations, acronyms, and alternate names in bulk. This is critical for duplicate detection.
- 🔄 Duplicate pages: Pages with overlapping content (e.g., "CoT" vs "思维链" created by older versions that didn't have alias-aware dedup). Click "Merge Duplicates" to fuse them and preserve all aliases.
- 💀 Dead links / Empty pages / Orphans: Standard wiki maintenance issues.
3️⃣ Use Smart Fix All Click "Smart Fix All" in the Lint report for a one-click, causality-ordered repair: aliases completed → duplicates merged → dead links fixed → orphans linked → empty pages expanded. This is the fastest way to clean up a wiki built across many versions.
4️⃣ Enable parallel page generation Settings → LLM Configuration:
- ⚡ Page Generation Concurrency: Set to 3 for most providers. Speeds up ingestion 2–3× on sources with 10+ entities.
- ⏱️ Batch Delay: Start at 300ms. Increase to 500–800ms if you hit rate limits.
5️⃣ Review current settings:
- 🌐 Wiki Output Language: Independent from UI language — your Wiki can be in Chinese while the plugin UI stays in English, or vice versa.
- 📊 Extraction Granularity: Five options control how deeply the LLM extracts entities from sources:
- Fine (~100 items) — Deep analysis, edge-case mentions included. High token cost, best for key sources.
- Standard (~50 items) — Balanced extraction. Good default for daily notes.
- Coarse (~10 items) — Quick overview, core entities only. Low cost, fast ingestion.
- Minimal (~5 items) — Essential items only. Ideal for batch processing 100+ files or testing new sources.
- Custom (1–300 items) — User-defined entity/concept limits for specialized workflows.
💡 Recommendation: Use Minimal or Coarse for large folders to save time and API costs. Use Fine selectively on key documents that warrant deep analysis.
- 🔄 Auto-Maintenance: Startup Quick Fixes defaults ON (one-time startup health check); File Watcher and Periodic Lint default OFF — enable only if you want automatic background processing.
🛡️ Safety: Parallel generation uses
Promise.allSettled— if one page fails, others continue. Failed pages are retried individually with exponential backoff. Smart Batch Skip automatically detects already-ingested files to save time and API costs.
⚡ What's New in v1.23.0
v1.23.0 is a MINOR feature release — the biggest architectural change since 1.0. Two major themes ship together: the Vercel AI-SDK v6 migration that replaces a hand-rolled 1625-line client with a stable, vendor-supported transport, and the Graph Engine — Personalized PageRank over the [[wiki-link]] graph — which delivers embedding-grade retrieval quality at zero embedding cost, works for every provider, and requires no new dependencies.
This release also folds in the v1.22.6 hotfix series (Test Connection regression fixes for GPT-5.x Pro variants and the LM Studio API-key gate), a knn-baseline evaluation gate, and a Sponsor section.
⭐ Highlights
- 🤖 Vercel AI-SDK v6 migration. The hand-rolled
OpenAICompatibleClient/AnthropicClient/AnthropicCompatibleClient(1625 LOC, 30+ provider-version workarounds accumulated since v1.20.0) is replaced by@ai-sdk/openai@3/@ai-sdk/anthropic@3/@ai-sdk/openai-compatible@2. Newsrc/llm-sdk/(5 files, 1421 LOC) +src/core/obsidian-fetch-bridge.ts(326 LOC) provide a stable, vendor-supported transport. Eliminates the entire class of provider-version regressions (#137 / #141 / #143 / #147 / #207). - 🕸️ Personalized PageRank over
[[wiki-link]]graph (Issue #198, #117, #157, #175). A new Monte-Carlo PPR engine walks the existing wiki-link structure to recover source pages via outgoing-link structure — embedding-grade R@k at zero embedding cost, offline, no new dependencies, works for every provider. Three-tier pipeline (lex fast path → LLM seeds → PPR walks) plus a hybrid guard (lex fallback when graph too small). Hub-link distinctiveness scanner shipped as a lint pass. - 🛡️ Provider-error UX hardening. Reasoning models (
gpt-5.1+,gpt-5.5,o1/o3/o4-mini) routed to OpenAI Responses API. Token-key probe-then-retry (max_tokens↔max_completion_tokens) on any HTTP 400 — no regex, no model-name hardcoding, justif 400 → retry with alt key. LM Studio API-key gate (Issue #223) lets local providers test connection without an API key. URL fallback auto-fixes missing/v1in custom baseURLs (Kimi Coding Plan).
✨ What's New
- 🔍 Personalized PageRank (PPR) engine.
core/monte-carlo-ppr.ts(Fogaras 2005 MC-PPR) performs K short random walks per query page at O(K×L) cost independent of |V| — embarrassingly parallel. Tuned on a 2142-page real vault:damping=0.05, numWalks=3000, walkLength=20improves R@5 from 21.5% → 23.8% (+11% relative). SeeREAL_VAULT_EVAL.mdfor the full tuning table. - 🎯 Hybrid retrieval cascade (PPR + LLM seeds + lex fast path).
core/ppr-cascade.ts(213 LOC) orchestrates the three-tier Query Wiki pipeline.core/section-extractor.ts(Tier B zero-LLM) replaces the previous LLM-based seed selection. - 🔗 Hub-link distinctiveness scanner (#157, #175). New lint pass that flags pages whose outgoing links mostly point to low-distinctiveness hubs (e.g., every page linking to
[[Index]]). 229 LOC + 15 tests. Contributed by @DocTpoint. - 🏷️ Hub-retirement crystallization signal (#215, @DocTpoint).
core/hub-retirement.ts(175 LOC + 12 unit tests + 136 LOC integration tests). Pure percentile-based verdict with dual absolute guards. Wired up for lint integration in v1.24.0. - 🤖 AI-SDK v6 client set.
openai-sdk-client.ts(455 LOC, auto Responses API routing for reasoning models),anthropic-sdk-client.ts(300 LOC, baseURL support for Coding Plan / z.ai / GLM-Antropic),openai-compat-sdk-client.ts(449 LOC, 8 OpenAI-format baseURLs).create-llm-client.ts(151 LOC) provides async + sync shim + preload pattern. - 🌐 Unified URL fallback for custom baseURLs.
core/url-fallback.ts(395 LOC) auto-resolves missing/v1in user-entered baseURLs (Kimi Coding Plan, GLM, z.ai). Module-level static cache survivescreateLLMClientre-creation so Ingest / Lint / Query all benefit from the first request's resolution. - 🔁 Token-key probe-then-retry (KISS, no regex).
src/llm-sdk/token-key-probe.ts(70 LOC) caches the workingmax_tokens↔max_completion_tokenskey per baseURL on first failure. Triggered byif (statusCode === 400 && !cached) → retry. Addresses root cause of #207 for all OpenAI-compatible gateways. - 🎬 Real-time streaming for all providers.
result.textStreamtrue逐块 streaming now works in all threellm-sdkclients. The "Restore true streaming for 3rd-party providers" backlog item is DONE. macrotask yield between chunks forces a paint frame per chunk (no more batch-arrival UX). - 🎉 Welcome note (Phase 5.1.5). Three-tier first-run Welcome note (Tier A empty / Tier B existing / Tier C upgrade).
type: welcomefrontmatter,createWelcomeNotetoggle,Recreate Welcome Notecommand. D8 LLM dynamic translation writes the note in the user's wiki language at write time — no hardcoded i18n. - 📥 Multi-File Ingest (Issue #130). Two-pane picker: left = recursive folder tree with per-file checkboxes, right = live ingest queue with status. "Add to queue" two-step flow, per-file cancel, "Cancel all" for pending/running jobs. Reuses
runBatchIngestso the per-file loop, dedup, and report modal are shared with folder ingest. NewIngestQueuepub/sub store is the single source of truth for in-session ingest lifecycle.
- 🔑 LM Studio API-key gate (Issue #223).
main.ts:962now excludes bothollamaandlmstudiofrom API-key validation. Local providers can test connection without an API key. - 🛡️ GPT-5.x Pro variants routing (Issue #207 follow-up, v1.22.6 hotfix).
gpt-5.1-pro/gpt-5.2-pro/gpt-5.5-procorrectly route to/v1/responses— broadened regex matches the trailing-prosuffix. - 🛡️ Auto Ingest completion path (Issue #204 follow-up, v1.22.6 hotfix).
trigger='auto'|'manual'field onIngestReport/IngestOptionsroutes auto-ingest completion toonAutoIngestDone(Notice) instead of the blockingIngestReportModal. - 📊 knn baseline analysis (P2-3 eval acceptance gate). DocTpoint ran a knn baseline (bge-m3, no graph) on the same
sample-50pagefixture per #198 follow-up: cascade R@5 27.1% vs knn 24.1% (3pp gap). Most of cascade's lift is semantic-over-keyword, not graph-over-semantic. Reinforces the 2026-06-22 #175 rejection — embeddings permanently rejected; graph signals are sufficient for all PPR use cases. - 🌍 i18n settings rewrite (10 locales). User-first language throughout ("disable thinking") instead of implementation details ("3-tier dialect fallback chain"). 14 new keys per locale for the Welcome note + Ingest modal UI.
- 💖 Sponsor section. Ko-fi button and 💖 Support the Project section in all 10 READMEs.
🔧 Improved
- 📜 Provider error body now reaches the Test Connection UI.
window.fetchre-fetch with 5s timeout captures the provider's diagnostic (e.g., "insufficient_quota") into the Notice. - ♻️ Lint performance knobs centralised.
src/constants.tsholds all yield cadences, batch sizes, and thresholds in one place — single-file tuning instead of 4-file drift. - ⏱️ 429/5xx exponential backoff on Responses API path. Previously only the Chat Completions path had retry; now both paths share the same
withRetry. - 🧹
thinkingControlCachedeprecated. Removed the 3-tier dialect probe; AI-SDK handles thinking internally. Cache retained on disk for backward-compat (will be removed in v1.24.0 if no use case surfaces). - ⚡ Bundle size 1.24 MB → 3.17 MB (user accepted 2026-06-29). Obsidian manifest has no size limit; lazy
await import()for AI-SDK packages didn't reduce bundle (esbuild CJS inline); future ESM bundle / dynamic chunk can revisit.
🐛 Fixed
- GPT-5.x models no longer fail Test Connection with 400 (#207) — full coverage including
-provariants. - LM Studio Test Connection no longer requires API key (#223) — local providers excluded from the API-key gate.
- #204 Auto Ingest no longer opens blocking modal — Notice path correctly wired.
- Real-time streaming was batched — fixed via macrotask yield +
result.textStream-only consumption. generation_completeno longer stamped ontolog.md/index.md/schema/(v1.22.3) —isInWikiContentFolder()guard restricts the stamp towiki/{entities,concepts,sources}/....- Dead-link stub fabrication class closed (#197) —
fixDeadLinkno longer creates AI-expanded stub pages.
📊 Tests
- 1376 tests passing across 100 files (+272 since v1.22.0).
We recommend upgrading — the AI-SDK migration eliminates a class of provider-version regressions (#137 / #141 / #143 / #147 / #207), and the Graph Engine delivers embedding-grade retrieval quality at zero embedding cost. If you use OpenAI-compatible gateways with custom baseURLs, the URL fallback + token-key probe-then-retry fixes should resolve connection issues without configuration changes.
✨ Features
📊 Knowledge Quality
- 🔍 Entity/Concept extraction — LLM extracts entities (people, organizations, products, events, etc.) and concepts (theories, methods, terms, etc.) from your notes and generates standalone Wiki pages. Flexible extraction granularity (minimal ~5, coarse ~10, standard ~50, fine ~100, custom 1–500) balances analysis depth with API cost.
- 🏷️ Mandatory page aliases — every generated page includes at least 1 alias (translation, abbreviation, variant) for cross-language duplicate detection.
- 🔄 Duplicate detection & merge — semantic tiered detection catches true duplicates (cross-language translations, abbreviations, spelling variants); smart LLM fusion merges content while preserving aliases.
- 🧩 Intelligent knowledge fusion — multi-source updates merge new information without duplication; contradictions are preserved with source attribution;
reviewed: truepages are protected from overwrite. - 📏 Content truncation guard — 8000 max_tokens with automatic stop_reason detection and 2× token retry, covering all providers.
- 📝 Original quote preservation — Mentions-in-Source sections preserve quotes in their original language (optional translation) for full traceability.
- 🎨 Customizable tag vocabulary (v1.18.0). Settings → Wiki → Tag Vocabulary Mode → Custom lets you define your own entity-type and concept-type tag lists (e.g.
Medical_Arzneimittel,法规). The plugin respects your vocabulary in extraction prompts and frontmatter validation; the existing Lint audit (Issue #85 v7) reports any page whose tags fall outside the active vocabulary.

🛠️ Maintenance
- 🔍 Lint health scan — single comprehensive report detects: duplicate pages, dead links, empty pages, orphans, missing aliases, contradictions.
- 🎯 Tiered semantic duplicate detection — Tier 1 (direct name match: cross-language, abbreviation, high-similarity titles) always verified; Tier 2 (indirect signals: shared links, medium similarity) fills token budget.
- ⚡ One-click Smart Fix All — batch fixes in causal order: fill aliases → merge duplicates → fix dead links → link orphans → expand empty pages, with per-phase popup report.
- 🏷️ Alias completion — one-click parallel batch generation of missing aliases, improving future duplicate detection.
- 🔄 Auto-maintenance — multi-folder watching, scheduled Lint, startup health check (all optional).
- ⚠️ Contradiction state machine —
detected → review-passed → resolved(AI-fix) ordetected → unresolved(manual). - 🛡️ Pre-ingest requirements gate (v1.21.0) — every source file is validated before any LLM call: empty/whitespace/frontmatter-only notes are rejected, and content-hash dedup catches identical files across paths. Prevents small/local models from hallucinating entity names on blank inputs.
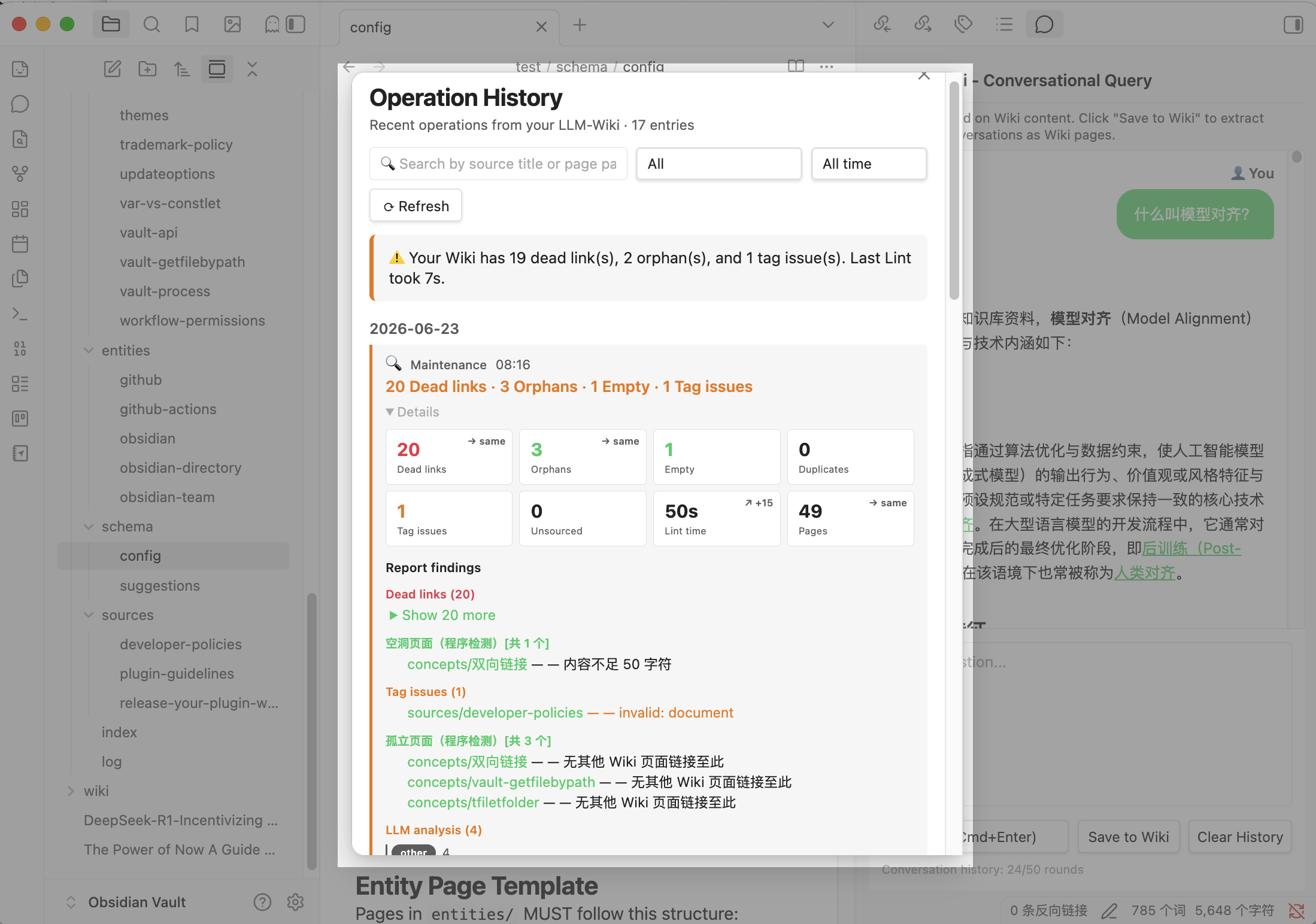
- 📊 Operation History Panel (v1.21.0) — searchable, filterable UI for past ingestions, lint reports, and maintenance runs, with insight-driven KPI cards and clickable page links.
- 🧹 Incomplete-page cleaner (v1.21.0) — pages left in a partial state after interrupted ingests are automatically archived on startup. Recoverable from Obsidian's
.trash.
💬 Query & Feedback
- 🤖 Conversational query — ChatGPT-style dialog with streaming Markdown output, automatic
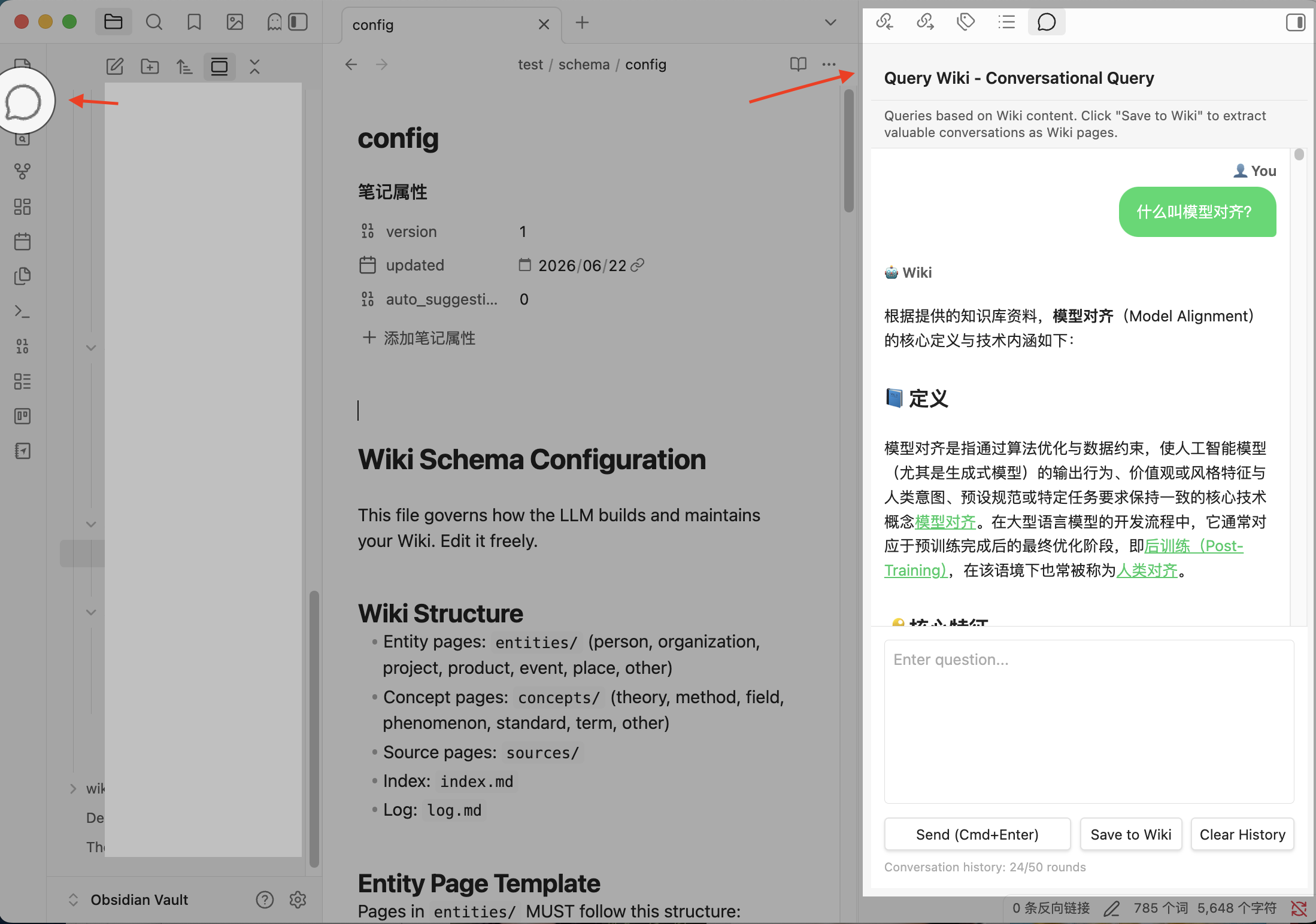
[[wiki-links]], and multi-turn history. - 🪟 Right-docked side panel (v1.22.1, PR #196). Query Wiki opens in a Copilot-style right sidebar leaf (reusing an existing leaf if already open) instead of a centered popup. The
message-circleribbon icon andQuery Wikicommand activate/reveal the panel; your notes stay visible alongside the conversation. All functionality is preserved unchanged.
- 📤 Query → Wiki feedback — save valuable conversations back into the Wiki, with entity/concept extraction and pre-save semantic dedup.
- 🔒 Duplicate-save guard — hash tracking prevents unchanged conversations from re-evaluating.
🌐 LLM & Language
- 🔌 Multi-provider support — Anthropic, Anthropic-compatible (Coding Plan), Gemini, OpenAI, DeepSeek, Kimi, GLM, MiniMax, LM Studio, OpenRouter, Ollama, custom endpoint.
- 🔄 5xx auto-retry — exponential backoff on HTTP 5xx / 429 / 529 across all clients (max 2 retries).
- 📋 Dynamic model list — fetched live from the provider API.
- 🌐 Wiki output language — 9 languages independent of UI (English / 中文 / 日本語 / 한국어 / Deutsch / Français / Español / Português / Italiano), with custom input option.
- 🌍 Full UI internationalization — plugin UI in 9 languages with 269+ UI fields fully translated to natural local expression.
- ⚡ Rate-limit guardian — automatically detects when parallel generation triggers rate limits and prompts to lower concurrency, increase batch delay, or switch provider.
- 🦙 Web Clipper compatibility — one-click addition of the official Obsidian Web Clipper's
Clippings/folder to the watch list; clipped web pages auto-ingest into the Wiki.
🏗️ Architecture & Performance
- ⚡ Parallel page generation — configurable 1–5 concurrent pages, default 3 (parallel), 2–3× speedup on large sources; per-page error isolation.
- 📚 Iterative batched extraction — adaptive batch sizing eliminates the long-document max_tokens bottleneck.
- 🏛️ Three-layer architecture —
sources/(read-only) →wiki/(LLM-generated) →schema/(co-evolved configuration). - 🧩 Modular codebase — 20+ focused modules in
src/.
🔒 Privacy & Security
- No backend, no tracking. The plugin runs entirely inside Obsidian — no external servers, no analytics, no data collection of any kind. Unless you actively configure an LLM provider, your notes never leave your vault.
- Data stays local by default. The plugin does not store, cache, or transmit your content anywhere outside of the LLM API you have chosen. Only the text you send for ingestion or query leaves your device — and only to the provider you configured.
- Full local mode via Ollama, LM Studio, or local providers. For complete data sovereignty, use a locally running LLM. Your notes are processed entirely on your machine — never touching the internet.
- Minimal permissions. Vault file access is used for Wiki management (reading notes, generating pages, detecting dead links). Network access is used only for communicating with your chosen LLM provider's API. Clipboard access is limited to the "Copy" button in the Query modal — used only when you click it.
⌨️ Commands
| Command | Description |
|---|---|
| 📥 Ingest single source | Select a note → generate Wiki pages with entities, concepts, and summary |
| 📂 Ingest from folder | Select a folder → batch generate Wiki from existing notes |
| 📑 Ingest multiple files | Open two-pane picker → select specific notes via per-file checkboxes → batch ingest the selection (with live queue + per-file cancel) |
| 🎯 Ingest current file | Quickly ingest the file you're currently editing (one-click) |
| 🔍 Query wiki | Conversational Q&A over your Wiki, streaming responses with [[wiki-links]] |
| 🛠️ Lint wiki | Full health scan: duplicates, dead links, empty pages, orphans, missing aliases, contradictions |
| 📋 Regenerate index | Manually rebuild wiki/index.md |
| 📊 View Ingestion History (v1.21.0) | Browse past ingestions, lint reports, and maintenance runs in a searchable, filterable UI |
| ⏹ Cancel current ingestion | Stop an in-progress operation cleanly at the next batch boundary |
Note: Schema update is no longer a top-level command. Schema suggestions are surfaced from inside the 🛠️ Lint wiki Modal — a single entry point so the user always sees the current schema context before applying changes. The Lint Modal's "Update Schema" button opens the IDE-style diff view (Issue #97).
📖 Example
Input: sources/machine-learning.md
### Machine Learning
Machine learning uses algorithms to learn from data.
### Types
- Supervised learning
- Unsupervised learning
- Reinforcement learning
Output — Concept page: wiki/concepts/supervised-learning.md
---
type: concept
created: 2025-12-01
updated: 2026-05-15
sources: ["[[sources/machine-learning]]"]
tags: [method]
aliases: ["监督学习", "Supervised Learning"]
---
### Supervised Learning
### Basic Information
- Type: method
- Source: [[sources/machine-learning]]
### Description
Supervised learning is a machine learning paradigm where models learn
from labeled training data to make predictions on unseen data...
### Related Concepts
- [[concepts/Machine-Learning|Machine Learning]]
- [[concepts/Unsupervised-Learning|Unsupervised Learning]]
### Related Entities
- [[entities/Arthur-Samuel|Arthur Samuel]]
### Mentions in Source
- "Supervised learning uses labeled data to train predictive models..."
🤖 Model Selection Guide
This plugin follows Karpathy's philosophy: feed the LLM full Wiki context, not chunked RAG retrieval. Long-context models are strongly recommended — the larger your Wiki grows, the more context the LLM needs.
💡 Why not RAG? Karpathy's original critique argues that RAG fragments knowledge and breaks the LLM's ability to reason across the full knowledge graph.
💰 Value-First Strategy: You don't need flagship models. The following cost-effective alternatives deliver excellent results at lower prices:
| Tier | Model | Context | Why |
|---|---|---|---|
| 🌟 Value Pick | DeepSeek V4-Flash | 1M tokens | Lowest cost ($0.14/M), 284B MoE, ideal for batch ingestion |
| 🌟 Value Pick | Gemini-3.5-Flash | 1M tokens | 4× faster output than GPT-5.5, great for agent tasks |
| 🌟 Value Pick | Qwen3.6-Plus | 1M tokens | Strong coding & agentic capabilities, competitive pricing |
| 🌟 Value Pick | Grok-4 | 2M tokens | xAI 2025-07 flagship, 2M context, strong reasoning & code tasks |
| Balanced | Claude Sonnet 4.6 | 1M tokens | Great quality/cost balance, $3/$15 per million tokens |
| Lightweight | Claude Haiku 4.5 | 200K tokens | Fast and affordable for smaller wikis |
| Budget | Xiaomi MiMo-V2.5 | 1M tokens | Xiaomi 310B/15B MoE, MIT open-source 2026-04, agent & multimodal |
| Flagship | Claude Opus 4.7 | 1M tokens | Ultimate quality, higher cost — use selectively |
| Flagship | GPT-5.5 | 1M tokens | Top reasoning, higher cost — use selectively |
For local models (Ollama): context windows are typically smaller (8K–128K). Consider using a cloud provider for ingestion + local model for query.
🔌 Anthropic Compatible (Coding Plan): If your provider offers an Anthropic-compatible API endpoint, select "Anthropic Compatible" and enter your provider's Base URL and API Key.
💡 Subscription plans: Coding Plan, OpenAI Pro, or Anthropic Pro plans are excellent options for cost control with frequent use. This plugin supports these services.
🏗️ Architecture
Karpathy's three-layer separation design:
sources/ # 📄 Your source documents (read-only)
↓ ingest
wiki/ # 🧠 LLM-generated Wiki pages
↓ query / maintain
schema/ # 📋 Wiki structure configuration (naming, templates, categories)
Codebase (src/):
main.ts # 🔌 Plugin entry point
wiki/ # Wiki engine modules
wiki-engine.ts # 🎯 Orchestrator
query-engine.ts # 💬 Conversational query
source-analyzer.ts # 📊 Iterative batch extraction
page-factory.ts # 🏗️ Entity/concept CRUD + merge
conversation-ingest.ts # 📥 Chat → wiki knowledge
contradictions.ts # ⚠️ Contradiction detection
system-prompts.ts # 🗣️ Language directive + section labels
lint/ # Lint sub-modules
controller.ts # 🔍 Lint orchestration
fix-runners.ts # ⚡ Batch fix execution helpers
scanners.ts # 🔍 Scanners (dead links, orphans, aliases, quote grounding)
duplicate-detection.ts # 🔄 Programmatic candidate generation
report-builder.ts # 📋 Pure-function report markdown builder
phases/ # Phased lint execution
prompts/ # LLM prompt templates by domain
schema/ # Schema co-evolution
manager.ts # 📋 Schema CRUD + suggestions
auto-maintain.ts # 🔄 File watcher + periodic lint + startup quick fixes
analyze.ts # 📊 Schema-analyze with cancel wiring
ui/ # User interface
settings.ts # ⚙️ Settings panel
modals.ts # 📦 Lint / Ingest / Query / History modals
core/ # 🧩 Pure function modules (zero IO, fully testable)
i18n, slug, json, frontmatter, tag-vocab, sources-normalizer, ...
+ shared: llm-client.ts, llm-client-wrapper.ts, texts.ts, prompts.ts, types.ts
Generated pages:
wiki/sources/filename.md— 📄 Source summarywiki/entities/entity-name.md— 👤 Entity pages (people, orgs, projects, etc.)wiki/concepts/concept-name.md— 💡 Concept pages (theories, methods, terms, etc.)wiki/index.md— 📑 Auto-generated indexwiki/log.md— 📝 Operation log
❓ FAQ
Keep your plugin updated. This project ships frequently — new features and fixes land every few days. Run Settings → Community Plugins → Check for updates regularly.
For more, see the FAQ Discussion on GitHub.
💡 General
What does the plugin actually do?
You drop notes in, it extracts people, concepts, and theories, then generates an interlinked wiki with [[bidirectional links]]. Ask questions and get answers grounded in your notes — not internet hallucinations.
Minimum requirements? Obsidian v1.11.0+, desktop (Windows/macOS/Linux), an LLM provider API key. Ollama works locally with no API key. See Configure an LLM Provider above.
Which model should I use? See Model Selection Guide above. Long-context models work best — the larger your wiki, the more context the LLM needs.
🏷️ Aliases & Duplicates
Why does Lint show "missing aliases" on almost all my pages? Pages generated before v1.7.11 didn't include aliases. This is harmless — aliases are an enhancement, not a bug. Click Complete Aliases in the Lint report to batch-generate translations, acronyms, and alternate names. Once aliases exist, duplicate detection and alias-aware search become much more effective.
Why do I see duplicate pages like "CoT" and "思维链"? Pre-v1.7.10 versions lacked alias-aware duplicate detection. Run Lint Wiki → Merge Duplicates to fuse them. The merged page preserves aliases from both, preventing future duplicates.
How does duplicate detection work? (v1.7.10+) Two-tier semantic detection: Tier 1 (always LLM-verified) catches cross-language matches, abbreviations, high-similarity titles. Tier 2 fills remaining token budget with moderate-similarity candidates. Aliases are critical for Tier 1 — run Complete Aliases if your pages are pre-v1.7.11.
What are "polluted pages"? (v1.9.0)
Pages with folder prefixes accidentally baked into filenames — e.g. concepts/concepts布局优化.md. Run Lint Wiki → 🧹 Fix Polluted Pages to rename and update all incoming links.
⚡ Performance & Cost
How do I speed up ingestion? In Settings → LLM Configuration: increase Page Generation Concurrency to 3–5 (parallel page creation), lower Batch Delay to 100–300ms (watch for rate limits). Choose "Minimal", "Coarse", or "Standard" Extraction Granularity to reduce page count and save API costs.
Why am I getting HTTP 429 errors? The plugin auto-detects rate-limiting and suggests: lower concurrency to 1–2, increase Batch Delay to 500–800ms, or switch to a higher-limit provider.
How do I control API costs?
- Auto-Maintenance is OFF by default (enable only if you need background processing)
- Smart Batch Skip automatically skips already-ingested files
- "Standard" or "Coarse" granularity = fewer LLM calls
- Batch Delay > 500ms spaces calls without increasing token usage
- Lint report shows counts before you run fixes — decide what's worth it
🧹 Maintenance
What does Smart Fix All do? Runs fixes in causality order (v1.9.0+):
- 🧹 Fix polluted pages → 2. 🏷️ Complete aliases → 3. 🔄 Merge duplicates → 4. 🔗 Fix dead links → 5. 🔗 Link orphans → 6. 📝 Expand empty pages
Lint freezes on a large Wiki? Upgrade to v1.7.17+ — Lint now yields to Obsidian's UI thread every 50 pages, preventing multi-second freezes even on 1200+ page wikis.
🔍 Troubleshooting
Why can't I use ingest/lint/query after installing? The plugin requires a successful connection test before core features unlock. Go to Settings → Karpathy LLM Wiki → pick a provider → enter your API key → click Fetch Models → select a model → click Test Connection. Once you see the green "LLM Ready" indicator, all features are available. This prevents silent failures from misconfigured providers.
How do I cancel a running ingestion or lint?
Click the status bar text during an operation (it shows "Ingesting... click to cancel"), or use Ctrl+P → "Cancel current ingestion". The operation stops cleanly at the next batch boundary, preserving all completed work.
How do I quickly ingest the file I'm currently editing?
Click the sticker icon in the left ribbon bar, or use Ctrl+P → "Ingest current file". This skips the file picker and directly ingests the active editor tab.
I see [[[[entities/Foo|Foo]]]] double brackets in my log.md — how do I fix this?
Run Lint Wiki — the scanner now automatically detects and fixes all double-nested wiki-links across your entire wiki directory (including log.md) with zero LLM cost. No manual cleanup needed.
Why am I getting "Overloaded" errors? The plugin now recognizes Anthropic's 529 overload error as retryable. Overload errors are automatically retried with exponential backoff across all providers.
Why was a duplicate stub created when the page already exists in entities/ or concepts/? The plugin now uses slug-based matching — different formatting of the same name resolves to the existing page instead of creating a duplicate stub.
Query can't find pages I know exist? Three common causes: (1) Index is stale → Regenerate index. (2) Missing aliases → Complete Aliases. (3) Try different phrasing — LLM does semantic matching, not keyword search.
Can I manually edit Wiki pages?
Yes. Set reviewed: true in frontmatter to protect from overwrite. Manual aliases, tags, and sources are preserved during merges.
Safe upgrade?
The plugin never modifies your source files. Backup wiki/ → update plugin → Regenerate index → Lint Wiki → fix selectively.
My local model (Ollama, LM Studio) is fabricating weird entity names from blank or frontmatter-only notes. (v1.21.0) Fixed in v1.21.0 by the pre-ingest requirements gate: empty/whitespace/frontmatter-only notes are now rejected before any LLM call, and content-hash dedup catches identical files across paths. Upgrade to v1.21.0+ to stop the empty-file hallucination class of bugs (small models filling in made-up entity names when given a blank prompt).
My sources/ files got renamed after upgrading to v1.20.3 — is something wrong? (v1.20.3+)
No — this is the new collision-safe source-slug fingerprint at work. Every sources/<slug>.md is now sources/<basename>_<6hex>.md (the hex is an FNV-1a hash of the file's full path). Files with the same basename across different folders (e.g. 11× About this course.md in Academy courses) no longer collide. Re-ingest renames existing sources/ pages in place and all [[sources/<slug>]] backlinks update automatically. If you have external scripts or bookmarks pointing to sources/<old-slug>.md, update them to the new fingerprinted names.
Will re-ingesting an unrelated source overwrite a page I locked with reviewed: true? (v1.20.3+)
No — Stage 4 (updateRelatedPage) now respects reviewed: true and routes to the append-only path, same as the ingest path. Your curated body survives verbatim; only genuinely new content is appended.
How do I get help?
- GitHub Issues — bug reports
- GitHub Discussions — questions & feedback
How do I collect debug logs for troubleshooting?
- Open Developer Tools (
Ctrl+Shift+I/Cmd+Option+I) - Go to the Console tab
- Run your operation (ingest, query, or lint)
- Look for messages with module name prefixes like
[Step],[LLM], module names - For local testing, use
pnpm build:devinstead ofpnpm buildto preserve full debug output - Copy the relevant log lines and include them in your GitHub issue — this makes bug diagnosis much faster
🔒 Transparency & Compliance
This plugin is listed on the Obsidian Community Plugin Market and undergoes automated review for security and permissions.
The plugin has no backend, no server infrastructure, and no data collection of any kind. It is purely local software running inside Obsidian. The plugin cannot and does not collect, store, or transmit your data to any server — because no such server exists.
Network access is used only to communicate with the LLM provider you configure — no other network calls are made. This is entirely under your control: you choose the provider, you enter the API key, you decide where your data goes.
File system access (vault enumeration) is required to build and maintain the wiki: reading your source notes, generating pages, scanning for dead links, and detecting duplicate pages. The plugin never modifies your source files — only files under the wiki folder.
Clipboard access is used exclusively by the "Copy" button in the Query modal, and only when you click it.
If you prefer complete data locality, use a local LLM provider such as Ollama or LM Studio. With a local provider, your data never leaves your machine.
💖 Support the Project
If LLM-Wiki has become a meaningful part of your knowledge workflow, you can support its ongoing development:
- ☕ Buy me a Ko-fi — one-time or monthly support via Ko-fi
- 💳 Tip via PayPal — one-time tip via PayPal
Sponsorship is entirely optional. The plugin stays MIT-licensed and feature-complete regardless.
Sponsors
Thanks to the following people for supporting the project:
📜 License
MIT License — see LICENSE.
🙏 Acknowledgments
- 💡 Concept: Andrej Karpathy's LLM Wiki — the original vision that inspired this plugin
- 🛠️ Platform: Obsidian Plugin API
- 🔌 LLM transport: Vercel AI SDK v6 (
@ai-sdk/openai,@ai-sdk/anthropic,@ai-sdk/openai-compatible) via ObsidianrequestUrl